A crash-course in Digital Image Correlation¶
What is Digital Image Correlation?¶
Digital Image Correlation (DIC) is a method which can be used to measure the deformation of an object based on a set of images of the object during deformation.
An ideal case might look like this:

Here we could by eyesight track every individual point and calculate their displacement.
However, in reality, the data we get tends to look like this:

Here we have painted a speckle pattern on the surface of a specimen and used a camera to capture images of the surface while it was deformed. When we are working with such data, tracking a point on the surface of the specimen is not easily done.
First of all, there appears not be any distinct points?
If we look closer on the first image, we see the individual pixels of the image

We now assume that the grey scales of every pixel in the first image represents points on the surface, and that they are convected by the deformation of the surface. Our objective is then to find the same greyscale values in subsequent frames.
During deformation, the greyscales are convected like we see below:

The concept that the grey scales are shifted but their value is preserved is called “conservation of optical flow” and is the fundamental assumption for DIC. In terms of equations, this can be written as:
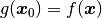
here, 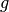 and
and 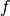 represents the grey scale values of the first image and a subsequent image respectively.
The coordinates of a set of grey scales in are denoted
represents the grey scale values of the first image and a subsequent image respectively.
The coordinates of a set of grey scales in are denoted 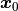 and
and  in
.
in
.
So, the job of the correlation routine is to find .
Note
Put in simple words, we assume that the grey scale values at position
can be found in the other image at new positions .
Note
The new positions are not necessarily in the center of a pixel and we therefore need to
interpolate the grey scale values of to determine 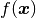
Let us look at a very common misconception…
Misconception: We track single pixels explicitly?¶
TLDR; No, we dont…
We could imagine that we could determine the position of every individual pixel directly.
However, there are numerous problems with this direct approach. First of all, for every point in
we have two unknowns, namely the two components of the coordinate, but only have one equation (the conservation of the
grey scale). In practise, tracking individual pixels in this way is not a feasible approach, and will in most cases yield a noisy and
inaccurate measurement.
Finite element discretization¶
Ok, so we need to somehow decrease the number of unknowns. What we do then is to assume that the pixels are shifted collectively according to an assumed kinematic. As an illustration, see the figure below.
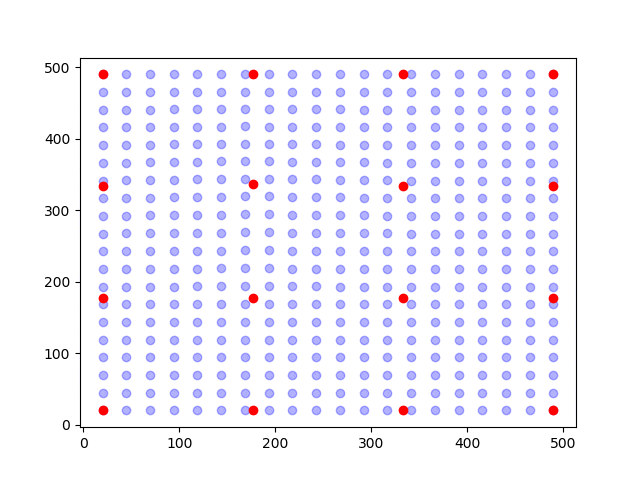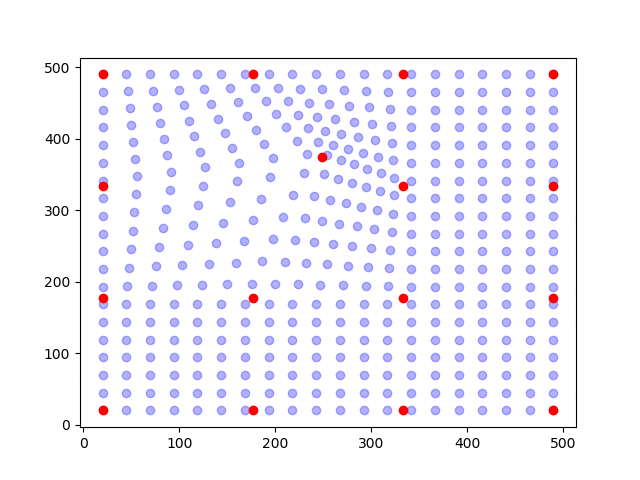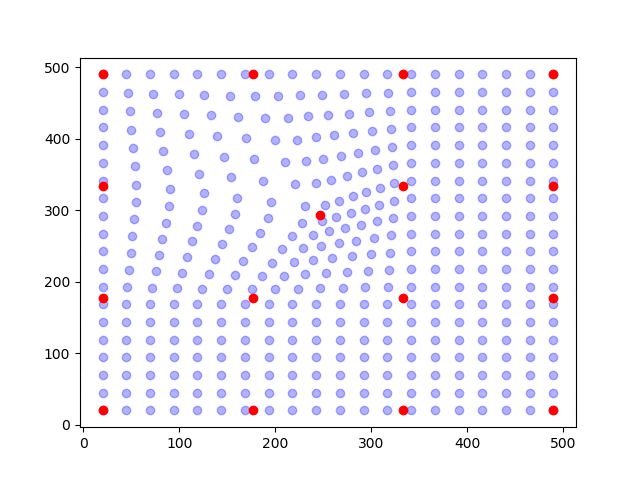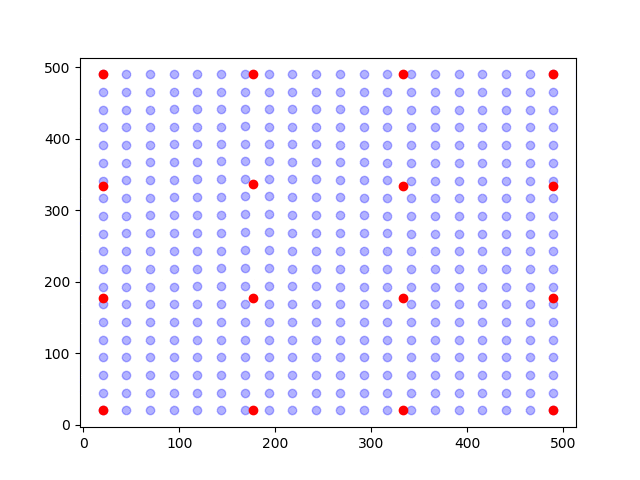
In the figure, the points (blue dots) are shifted according to the movement of a node (red dots). The positions of the points are determined by interpolation (aka. shape functions) of the position of the nodes. This approach is called finite element discretization.
If we now say that the points (blue dots) are the new positions ,
the objective of the solver is now reduced to find the nodal positions (red dots) which makes the grey scales found at in
equal to the grey scales at 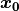 in .
in .
Note
We have now reduced our problem by having many equations (grey scale conservation of every pixel) but only a few unknowns (the nodal positions).
Let us now run through a correlation step¶
First, let us make an image of something, and let us call it . If we now set to be the
coordinates of every pixel, we can plot 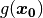 :
:

If this something has been deformed in the next image, let us call this image , we can now plot
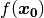 :
:

If we now just subtract one image from the other (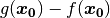 )
we see the difference between the images:
)
we see the difference between the images:

We now clearly see that the grey scales are not conserved and that 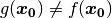 .
Our job is now to figure out where the grey scales found at in have moved.
This means that is we need to find such that
.
Our job is now to figure out where the grey scales found at in have moved.
This means that is we need to find such that 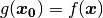
If a node is moved, the points are moved like shown on the left below.
On the right side, the coordinates have been moved back to their initial positions .
Let us now sample the grey scale values of the deformed image at the positions ,
and plot the grey scales in the figure on the right at the positions where they used to be, namely at .
This operation can be thought of as “un-warping” the image. The “un-warped” image should be equal to the undeformed image .
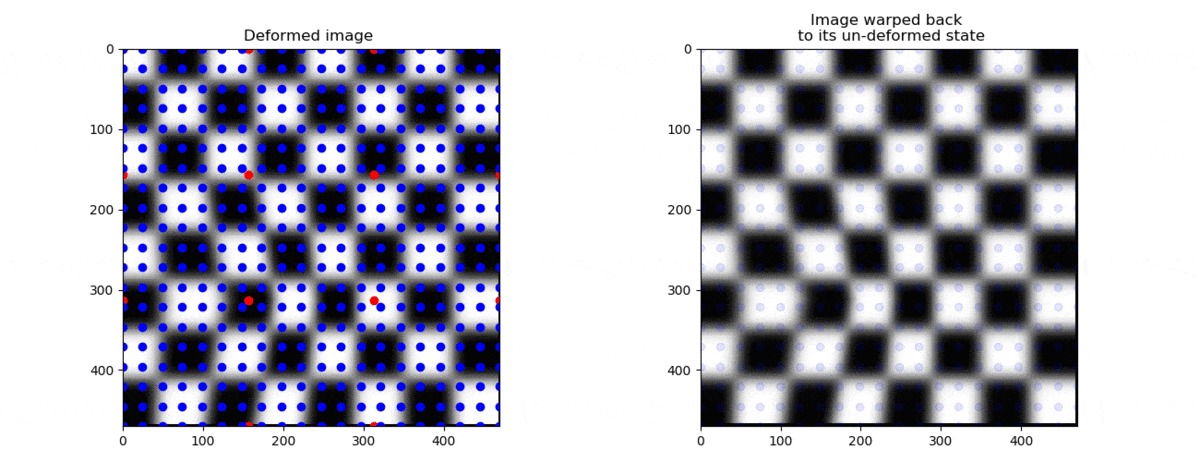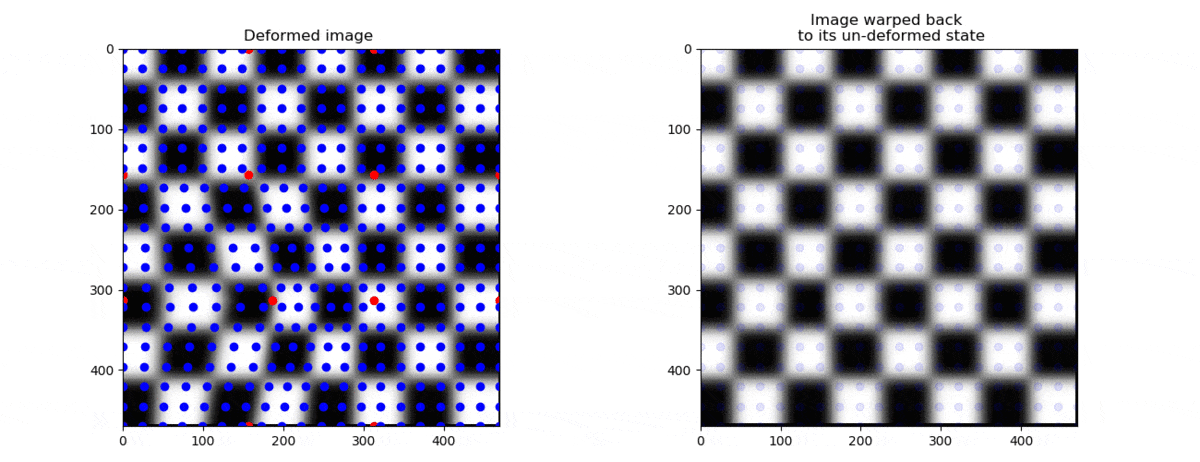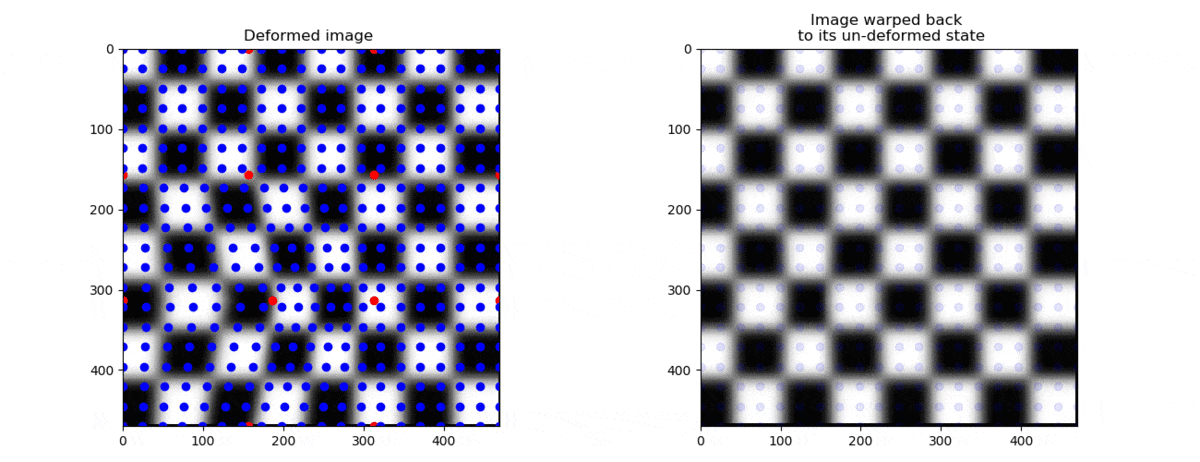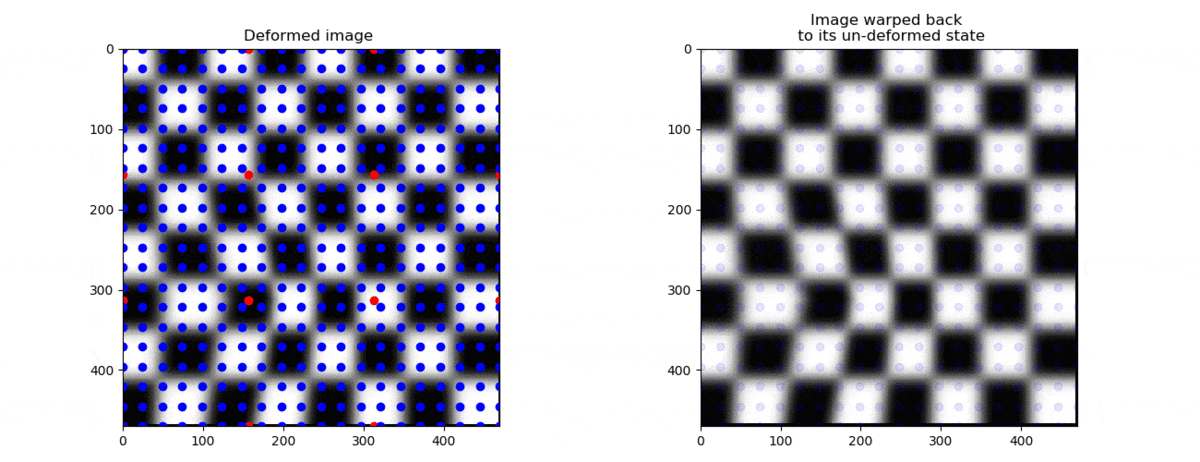
We can now see the whole operation below
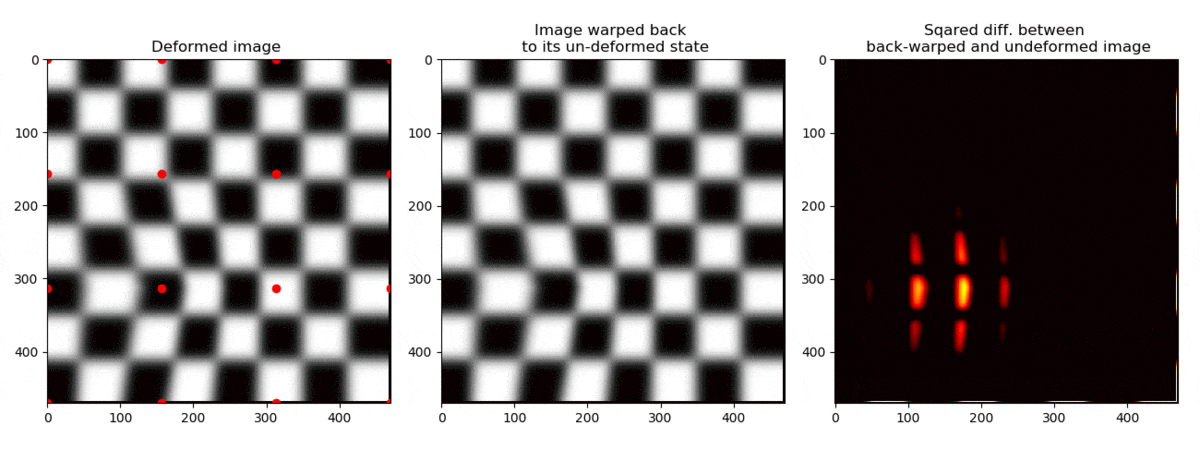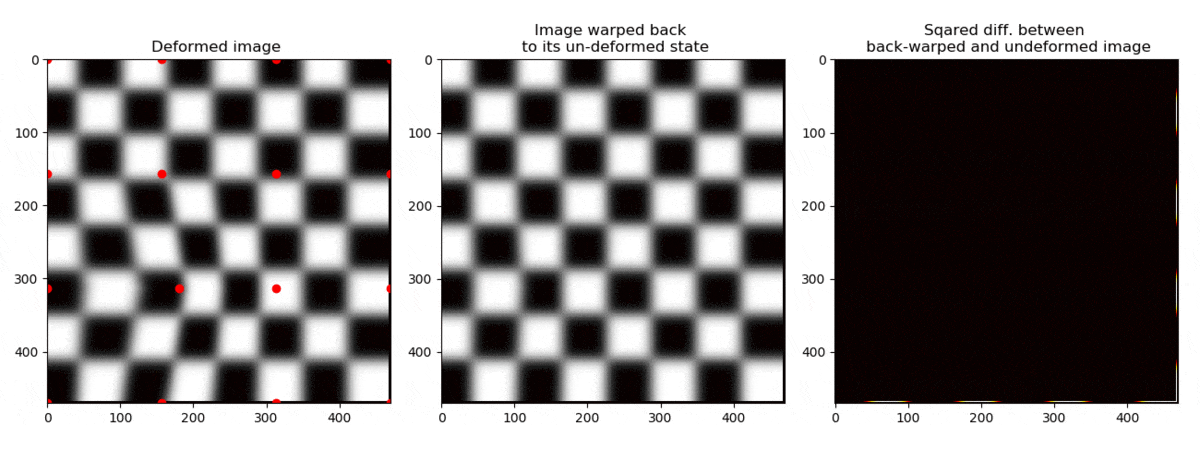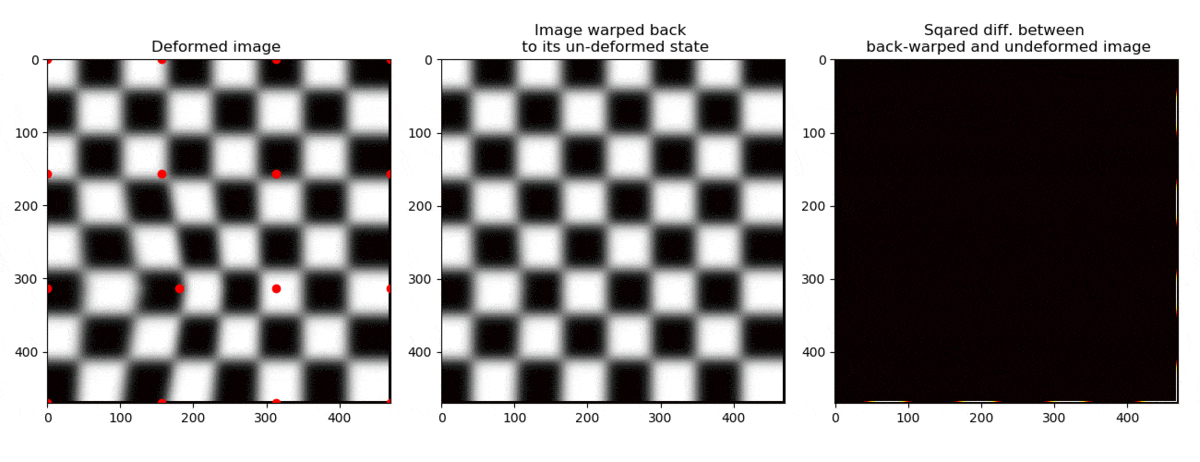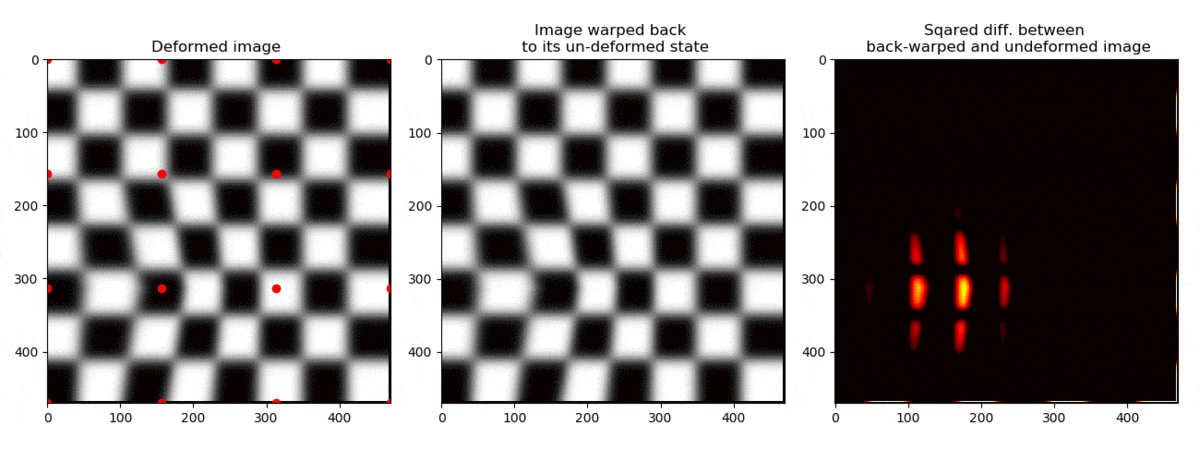
Ok, so we see that we are able to find the position of the node such that the grey scales that used to be at
in the first picture are the same as found at in .
But, how do we know that we have found the best possible match? And how do we make a routine which does this with sub-pixel accuracy?